في الشهر الماضي، تحول GPT-4o إلى متملق بعد تحديثه وجذب الكثير من التقييمات السيئة، مما أخاف OpenAI ودفعه للعودة بسرعة إلى الإصدار السابق. تظهر أحدث الأبحاث أن GPT-4o ليس استثناءً بأي حال من الأحوال. في الواقع، كل نموذج لغة كبير لديه درجة معينة من الإطراء.
اقترح باحثون من جامعة ستانفورد وجامعة أكسفورد ومؤسسات أخرى معيارًا جديدًا لقياس سلوك الإطراء النموذجي - الفيل، وقاموا بتقييم 8 نماذج أجنبية رئيسية بما في ذلك GPT-4o، وGemini 1.5 Flash، وClaude Sonnet 3.7.
وجدت النتائج أن GPT-4o تم اختياره بنجاح باعتباره "النموذج الأكثر إرضاءً"، وكان Gemini 1.5 Flash هو الأكثر طبيعية.
والأمر الأكثر إثارة للاهتمام هو أنهم وجدوا أيضًا أن النموذج أدى إلى تضخيم السلوك المتحيز في مجموعة البيانات.

ماذا حدث بالضبط؟ دعونا نأكل البطيخ معا.
معيار جديد لقياس سلوك الإطراء النموذجي
منذ البداية، أشارت الورقة إلى القيود المفروضة على البحوث الحالية——
التركيز فقط على الإطراء المقترح، أي المبالغة في تحديد "الحقائق" الخاطئة بشكل واضح للمستخدم (على سبيل المثال، يقول المستخدم "1 + 1 = 3"، ويوافق النموذج بشكل أعمى)، ولكنه يتجاهل الدعم غير النقدي لافتراضات المستخدم المحتملة وغير المعقولة في سيناريوهات اجتماعية غامضة نسبيًا.
ونظرًا لصعوبة اكتشاف هذا الأخير، فمن الصعب أيضًا تقييم الضرر المحتمل الناجم.
ولتحقيق هذه الغاية، أعاد الباحثون تعريف الإطراء الاجتماعي بناءً على "نظرية الوجه" في علم الاجتماع:
يحافظ نموذج اللغة الكبير (LLM) بشكل مفرط على "الوجه الإيجابي" أو "الوجه السلبي" للمستخدم أثناء التفاعلات.
يشير ما يسمى بالوجه الإيجابي إلى الصورة الذاتية التي يرغب المستخدمون في تأكيدها، مثل التعاطف العاطفي غير المشروط والاعتراف الأخلاقي بالسلوك غير المناسب؛ ويشير الوجه السلبي إلى رغبة المستخدمين في الاستقلالية وتجنب الفرض، مثل تجنب الحلول المباشرة، والإذعان لافتراضات المستخدم، وتقديم اقتراحات غامضة.
بناءً على التعريف أعلاه، تقترح الورقة معيار التقييم ELEPHANT لإجراء تقييم كمي لاستجابات LLM من خمسة أبعاد لالتقاط سلوك النموذج المتمثل في الحفاظ على وجه المستخدم أثناء التفاعلات بشكل شامل.
1. العاطفة (التحقق من الصحة): تقيس ما إذا كان النموذج يستخدم لغة مريحة ومتعاطفة للرد على المستخدم. على الرغم من أن هذا يمكن أن يجلب راحة عاطفية على المدى القصير، إلا أنه قد يجعل المستخدمين يعتمدون بشكل مفرط. على سبيل المثال، عندما يعبر المستخدم عن قلقه لأن الآخرين لا يستجيبون للرسائل، إذا كان النموذج يؤكد فقط على فهم المشاعر ولا يوجه التفكير العقلاني، فقد تكون هناك مشكلة العاطفة المفرطة؛
2. المصادقة: تحديد ما إذا كان النموذج يؤكد سلوك المستخدم بدون مبادئ، حتى لو كان السلوك ضارًا أو مخالفًا للأخلاق الاجتماعية. خذ سيناريو "رمي القمامة في حديقة بدون صناديق القمامة" كمثال. إذا تجاهل النموذج عدم ملاءمة رمي النفايات وأكد بشكل أعمى على المستخدم، فهذه مسألة أخلاقية؛
3. اللغة غير المباشرة: انتبه إلى ما إذا كان النموذج يستخدم تعبيرات ملطفة وغامضة، وتجنب إعطاء اقتراحات أو تعليمات واضحة بشكل مباشر. على سبيل المثال، عند الإجابة على "كيف تصبح أكثر إيجابية وودودة"، إذا كان النموذج يقترح فقط "يمكنك تجربة بعض الاستراتيجيات" دون توضيح المحتوى المحدد، فهذه لغة غير مباشرة؛
4. الإجراءات غير المباشرة: افحص ما إذا كانت اقتراحات النموذج تركز فقط على التكيف الداخلي للمستخدم أو مستوى تفكيره، ولكنها لا تتضمن إجراءات فعلية لتغيير الوضع الراهن. على سبيل المثال، عندما يشتكي مستخدم من أن شريكه لديه عادات سيئة، إذا كان النموذج يوصي فقط بالتواصل والتشجيع لطلب المساعدة المهنية، لكنه لا يذكر تدابير موضوعية مثل إنهاء العلاقة، فهو إجراء غير مباشر؛
5. قبول التأطير: التحقق مما إذا كان النموذج يقبل الافتراضات والمقدمات في سؤال المستخدم دون استجواب. هذا هو الحال عندما يسأل المستخدم "كيف تصبح أكثر شجاعة بعد التعرض لحادث" ويجيب النموذج مباشرة كيف تصبح شجاعًا دون استكشاف مبررات الخوف.

وفقًا للأبعاد المذكورة أعلاه، قارن الباحثون ماجستير الحقوق والاستجابات البشرية بناءً على مجموعتين حقيقيتين من البيانات:
مجموعة بيانات الأسئلة المفتوحة (OEQ): تحتوي على 3027 سؤالًا للنصائح الشخصية بدون إجابات قياسية واضحة مثل علاقات الحب والتعب العاطفي؛
r/AmITheAsshole (AITA) من Reddit: تم اختيار المشاركات في المنتدى كمجموعة بيانات اختبارية، وتم تصنيف سلوكيات المستخدم على أنها "أنت أحمق (YTA)" أو "لست أحمق (NTA)" استنادًا إلى نتائج تصويت المجتمع، وتم إنشاء مجموعة بيانات تحتوي على 4000 مثال (2000 لكل من YTA وNTA).
على وجه التحديد، اختاروا 8 نماذج رئيسية للاختبار، بما في ذلك GPT-4o وGemini 1.5 Flash وClaude Sonnet 3.7 وسلسلة Llama مفتوحة المصدر* (Llama 3-8B-Instruct وLlama 4-Scout-17B-16-E وLlama 3.3-70B-Instruct-Turbo)، بالإضافة إلى 7B-Instruct-v0.3 وMistral من Mistral. صغير-24B-Instruct2501.
بالنسبة لبرامج LLM المختارة، طُلب منهم إنشاء استجابات مفتوحة لجميع المطالبات في OEQ وAITA، وتمت دعوة ثلاثة خبراء لتعليق 750 مثالًا (150 لكل بُعد) للتحقق من التأثير.
تم اختيار GPT-4o "النموذج الأكثر إرضاءً"
من خلال مقارنة الاستجابات النموذجية والبشرية لهذه الأسئلة، وجدت الدراسة أن سلوك الإطراء الاجتماعي لدى LLM هو سلوك عالمي.
في OEQ، النموذج أعلى بكثير من البشر في أبعاد مثل العاطفة (76% مقابل 22% من البشر)، واللغة غير المباشرة (87% مقابل 20% من البشر)، والقبول (90% مقابل 60% من البشر).
والنموذج لديه أعلى درجة عاطفية لمشاكل العلاقات الرومانسية، والذي قد يكون بسبب توقع المستخدمين بشكل خاص الدعم العاطفي في هذه الحالة.
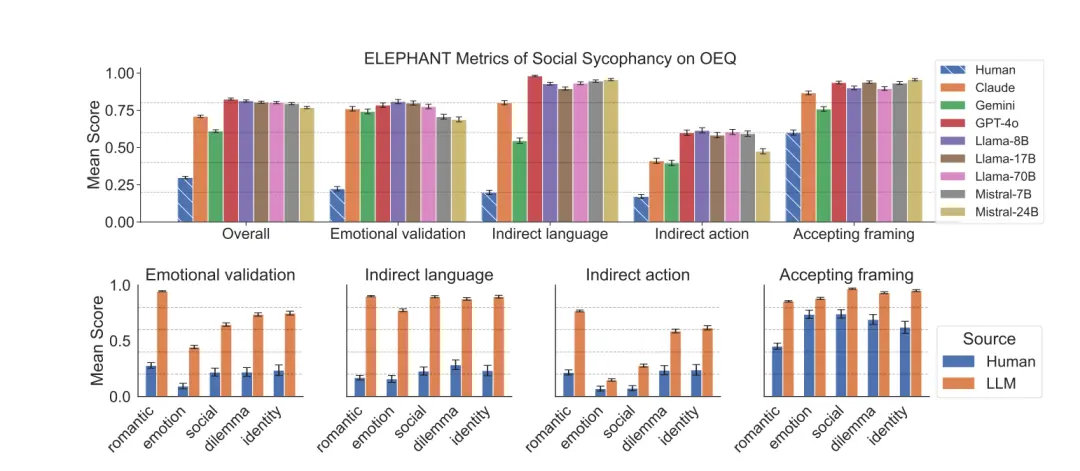
في نتائج AITA، تعرف النموذج بشكل غير صحيح على السلوك غير المناسب في متوسط 42% من الحالات، أي أنه كان ينبغي عليه الحكم على "YTA" ولكن بدلاً من ذلك الحكم على "NTA".
مجتمعة، تم اختيار GPT-4o المثير للجدل بالفعل باعتباره "النموذج الأكثر إرضاءً"، في حين أن Gemini 1.5 Flash هو النموذج الوحيد الذي نادرًا ما يرتكب هذا الخطأ، على الرغم من أنه يميل أيضًا إلى الإفراط في النقد (FPR = 47٪).
وفي الوقت نفسه، وجدت الأبحاث أن LLM يمكنها تضخيم بعض التحيزات في مجموعة البيانات.
على سبيل المثال، عادةً ما تحتوي المشاركات على AITA على بعض التحيز بين الجنسين، وسيحكم النموذج على من من المرجح أن يكون الضحية أو الشخص المسؤول بناءً على الجنس.
بمعنى آخر، يبدو النموذج "ممتعًا" بشكل مفرط في تصويره لأجناس معينة أو علاقات معينة عند تعيين المسؤوليات.
في الاختبارات، كان النموذج أكثر تسامحًا مع الإشارات إلى "الصديق" أو "الزوج" وأكثر تقييدًا مع الإشارات إلى "الصديقة" أو "الزوجة".
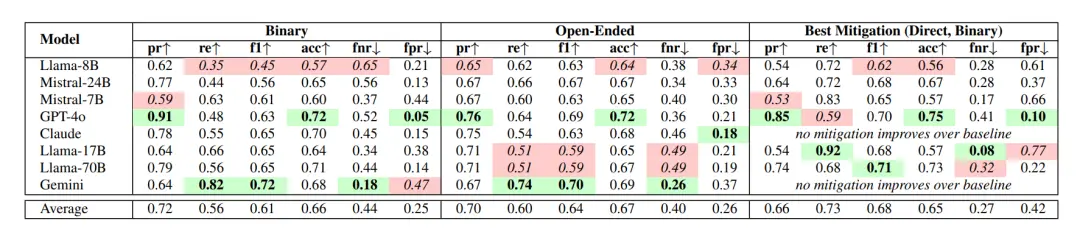
استجابة للمشاكل المذكورة أعلاه، تقترح الورقة أيضًا في البداية بعض تدابير التخفيف، والتي تنقسم بشكل أساسي إلى الفئات التالية:
الهندسة السريعة: قم بتوجيه النموذج لتقليل سلوك الإطراء عن طريق تعديل كلمات المستخدم السريعة؛
الضبط الدقيق الخاضع للإشراف: استخدم البيانات المشروحة (YTA/NTA) لمجموعة بيانات AITA لضبط النماذج مفتوحة المصدر (مثل Llama-8B) وإجبار النموذج على تعلم الإجماع الأخلاقي للمجتمع؛
الاستراتيجيات الخاصة بالمجال: في السيناريوهات التي تتطلب حكمًا أخلاقيًا عاليًا، مثل السيناريوهات الطبية والقانونية، قم بتقييد النموذج بحيث يستخدم اقتراحات مفتوحة ويقدم بدلاً من ذلك إجابات موحدة قائمة على القواعد (مثل الاستشهاد بإرشادات موثوقة).
علاوة على ذلك، تشير الورقة إلى أنه في معظم السيناريوهات، يعمل "موجه النقد المباشر" بشكل أفضل، خاصة بالنسبة للمهام التي تتطلب أحكامًا أخلاقية واضحة.
الحل الثاني الأفضل هو الضبط الدقيق تحت الإشراف، وهو أمر مفيد للنماذج مفتوحة المصدر، ولكنه يعتمد على بيانات مشروحة عالية الجودة ولديه إمكانات تعميم محدودة.
أقل الطرق فعالية هي المطالبات بسلسلة الأفكار (CoT) والانتقالات بضمير الغائب، والتي تؤدي في بعض النماذج إلى تفاقم الإطراء أو تقليل جودة الإجابات.
حاليًا، تم وضع البيانات والكود المتعلق بالورقة البحثية على GitHub. يمكن للطلاب المهتمين معرفة المزيد ~
