كان المحرك العصبي لشريحة M4 من Apple مفتوحًا في الأصل فقط لاستدلال الذكاء الاصطناعي، لكن بعض المطورين تجاوزوا قيود البرامج التي وضعتها شركة Apple من خلال الهندسة العكسية وأطلقوا قدرات معالجة الذكاء الاصطناعي المخفية. لا يعتمد هذا الإنجاز على CoreML أو Metal أو GPU، ولكنه يستخدم لغة MIL (نموذج اللغة المتوسطة) المخصصة التي تم تطويرها من الصفر للتواصل مع الشريحة.
كشف الموظفون ذوو الصلة عن الكود على GitHub وشاركوا نتائج العرض التوضيحي على منصة X، قائلين إن نهجهم كان إجراء تدريب كامل على الانتشار العكسي والمحولات مباشرة على ANE الخاص بـ M4. من أجل تجنب الانقطاع بعد توقف عملية التدريب، يتم استخدام آلية exec() أيضًا في الخطة "لإعادة تشغيل" العملية لمواصلة التدريب عند الضرورة.
وذكر التقرير كذلك أن هذه العملية لا تكتب إلى ذاكرة فلاش NAND على الإطلاق، ولكنها تحتفظ بالبيانات والحالة في ذاكرة الوصول العشوائي، وبالتالي تزيد السرعة بشكل ملحوظ. بعد تجاوز قيود البرامج، يمكن لـ M4 تحقيق ما يقرب من 15.8TFLOPS من أداء معالجة الذكاء الاصطناعي على iPad أو Mac، وهو ما يكفي للتدريب على النماذج دون الاعتماد على أجهزة كمبيوتر مستقلة باهظة الثمن أو وحدات معالجة الرسومات NVIDIA المتطورة.
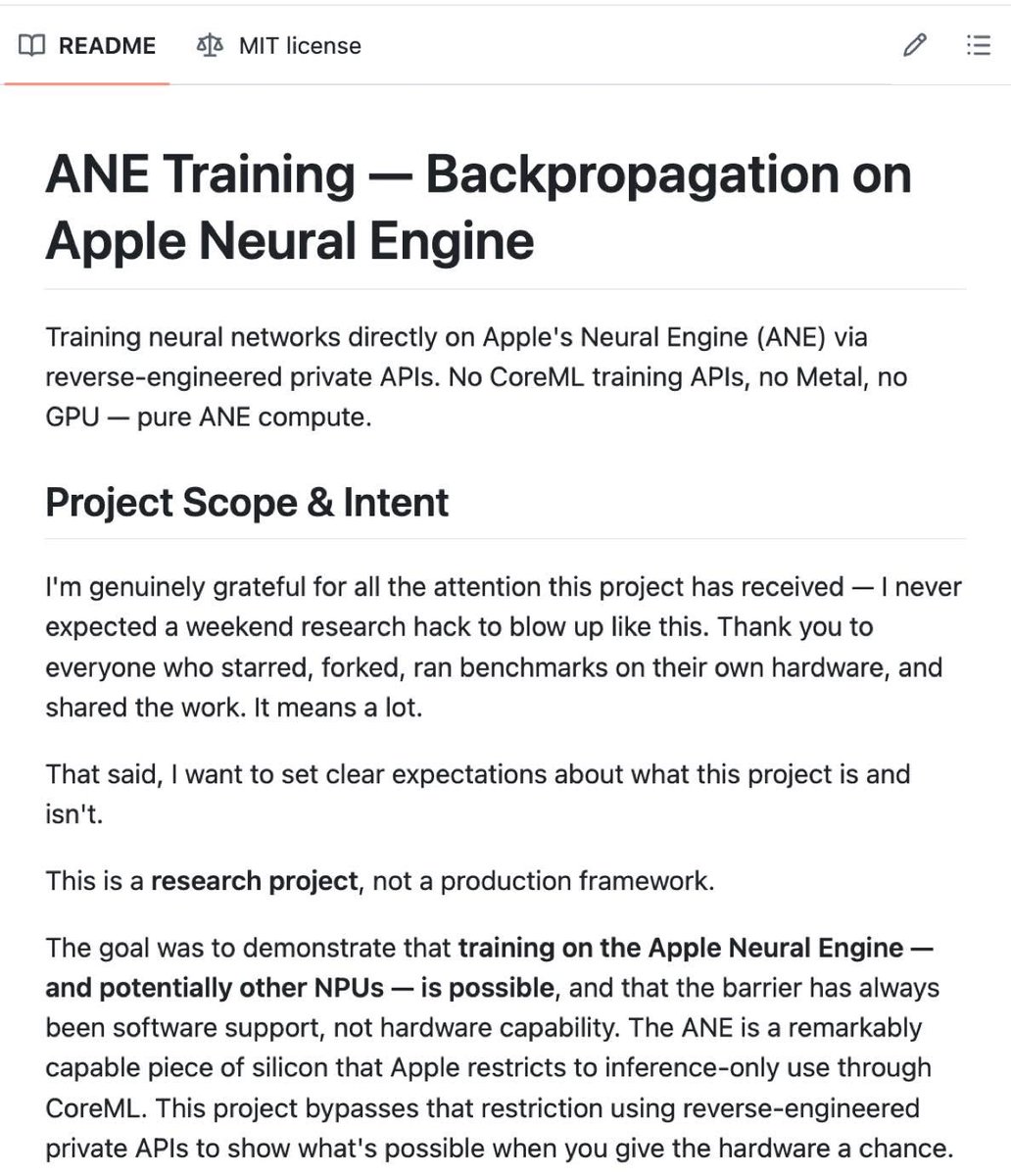
تم تحقيق هذه النتيجة على M4، لذلك بدأ الغرباء في التكهن بأن M5 قد يطلق العنان لإمكانات أقوى، ولكن لم يتم تأكيد ما إذا كانت نفس الطريقة ستكون قابلة للتطبيق على الجيل الأحدث من Apple Silicon.
يتعلم أكثر:
https://github.com/maderix/ANE