GPT-5.6 موجود، لكن... ما هو نموذجه؟ هذه المرة، لم تستخدم OpenAI الأسماء المألوفة مثل Pro وMini وInstant في الماضي. وبدلا من ذلك، جاء بثلاثة أسماء في وقت واحد:جي بي تي-5.6 سول، جي بي تي-5.6 تيرا، جي بي تي-5.6 لونا.سول هي الشمس، وتيرا هي الأرض، ولونا هو القمر.
يبدو خياليًا، مثل نموذج الكون الجديد. لكنها في الواقع طبقات المنتج التي نعرفها: أقوى نموذج رئيسي، ونموذج متوازن للاستخدام اليومي، ونموذج خفيف الوزن ورخيص، وسريع، ومناسب للمكالمات واسعة النطاق.
البيان الرسمي من OpenAI هو:ستكون سلسلة GPT-5.6 مفتوحة بالكامل في الأسابيع المقبلة، ولكنها حاليًا في معاينة محدودة لمجموعة صغيرة من "الشركاء الموثوقين" في Codex وAPI بناءً على طلب حكومة الولايات المتحدة.
دعونا أولا نلقي نظرة على المعلومات الاستخباراتية المتاحة للجمهور.

أعلى درجة هي نفس سعر GPT 5.5
قامت OpenAI بتعيين GPT-5.6 بثلاثة مستويات هذه المرة: Sol وTerra وLuna.
وبحسب البيان الرسمي، فإن Sol هو النموذج الرئيسي، وTerra هو نموذج متوازن للعمل اليومي، وLuna هو نموذج سريع ورخيص وخفيف الوزن.
تم إصدار النماذج ثلاثية المستويات دفعة واحدة، وهي تتوافق بشكل أساسي مع الهيكل ثلاثي المستويات الأكثر شيوعًا في منتجات النماذج الكبيرة: النموذج الأقوى هو المسؤول عن الحد الأعلى من القدرات، والنموذج المتوسط هو المسؤول عن معظم المهام اليومية، والنموذج خفيف الوزن هو المسؤول عن السرعة والتكلفة والمكالمات المتزامنة العالية.
ويمكن رؤية مستوى الثلاثة من السعر.
وفقًا لسعر API الذي أعلنته OpenAI،يتم تحصيل GPT-5.6 لكل مليون رمز مميز: تبلغ تكلفة Sol 5 دولارًا أمريكيًا للإدخال و30 دولارًا أمريكيًا للمخرجات؛ تبلغ تكلفة Terra 2.5 دولارًا أمريكيًا للمدخلات و15 دولارًا أمريكيًا للمخرجات؛ وتبلغ تكلفة Luna دولارًا أمريكيًا واحدًا للمدخلات و6 دولارات أمريكية للمخرجات.
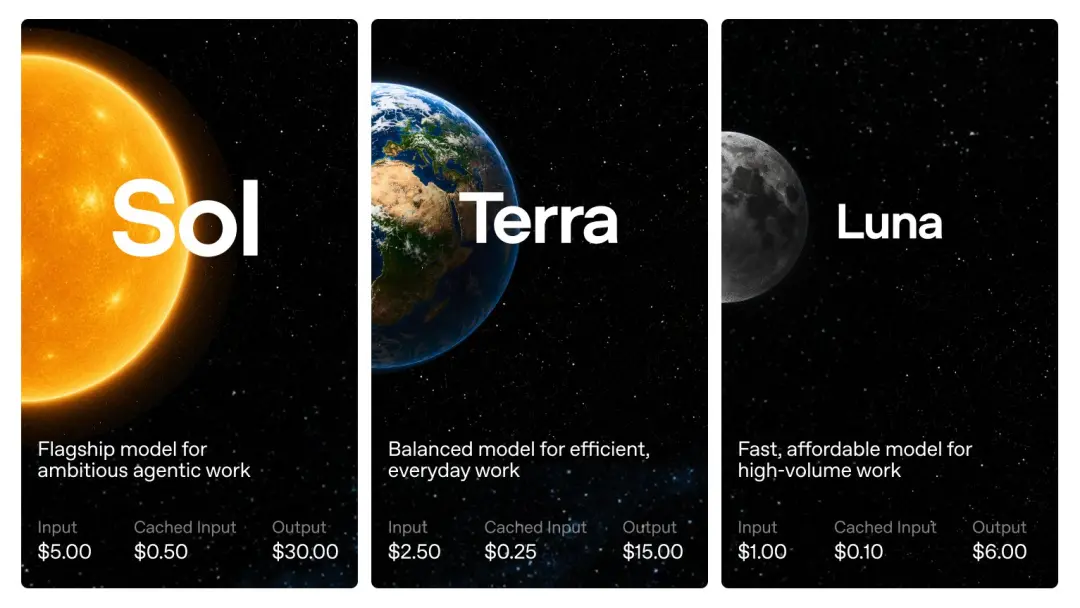
أعتقد أنك ربما لاحظت: على الرغم من أن GPT-5.6 Sol هو نموذج رئيسي من الجيل الجديد، إلا أن السعر يتماشى مع الإصدار القياسي GPT-5.5، وليس GPT-5.5 Pro.
انخفض Terra مباشرة إلى نصف GPT-5.5، وكان Luna خمس GPT-5.5 فقط.
لا يزال GPT-5.5 Pro هو أغلى طراز من OpenAI في الوقت الحالي. السعر هو 30 دولارًا أمريكيًا/مليون رمزًا للمدخلات و180 دولارًا أمريكيًا/مليون رمزًا للمخرجات. السعر هو 6 أضعاف سعر الإصدار القياسي GPT-5.5 وGPT-5.6 Sol. لا أعرف ما إذا كان سيكون هناك عالم GPT-5.6 آخر "أكثر ملاءمة للمهام المهنية" في المستقبل (فقط أمزح).
Sol هو الطراز الأعلى في سلسلة GPT-5.6، وهو أيضًا النموذج الذي يقضي معظم الوقت في تقديمه في الإعلان الرسمي.
تطلق OpenAI على GPT-5.6 Sol أقوى نموذج حاليًا، مع التركيز على قدراته في مجال التشفير والأبحاث البيولوجية وأمن الشبكات.
وبكل بساطة، تم تصنيف سول على أنه "النموذج الأفضل". وهو لا يتوافق مع سيناريوهات الدردشة العادية، بل مع المهام الأكثر تعقيدًا والأقرب إلى العمل الحقيقي.
على سبيل المثال، في سيناريو التعليمات البرمجية، يمكنه الاستمرار في التقدم حول الهدف: فهم المشكلة أولاً، ثم تقسيم الخطوات، ثم استدعاء الأدوات، وتشغيل الأوامر، والتحقق من النتائج، وإجراء التصحيحات في حالة حدوث أخطاء حتى اكتمال المهمة.
من أجل دعم Sol في معالجة المهام الأكثر صعوبة، قدمت OpenAI آليتين جديدتين إلى GPT-5.6.
الأول يسمىأقصى جهد المنطقوالتي يمكن ترجمتها على أنها "أقصى قوة تفكير".
الفهم الشعبي يعني أن لدى سول مزيدًا من الوقت للتفكير بوضوح في المشكلة ويستغرق وقتًا أطول لإجراء تفكير متعمق. إنها مناسبة للمهام المعقدة التي لا يمكن حلها عن طريق رد الفعل الأول.
والثاني يسمىالوضع الفائق,يمكن فهمه على أنه "الوضع الفائق".
ينصب تركيز هذا النموذج على السماح للعديد من الوكلاء الفرعيين بالمشاركة في المهام المعقدة معًا. يمكن فهم ذلك على النحو التالي: في الماضي، كان مساعد الذكاء الاصطناعي يعمل بمفرده، ولكن الآن يقود "مدير الذكاء الاصطناعي" العديد من المساعدين للتعامل مع المشكلات بشكل منفصل، وبالتالي تسريع تقدم العمل المعقد.
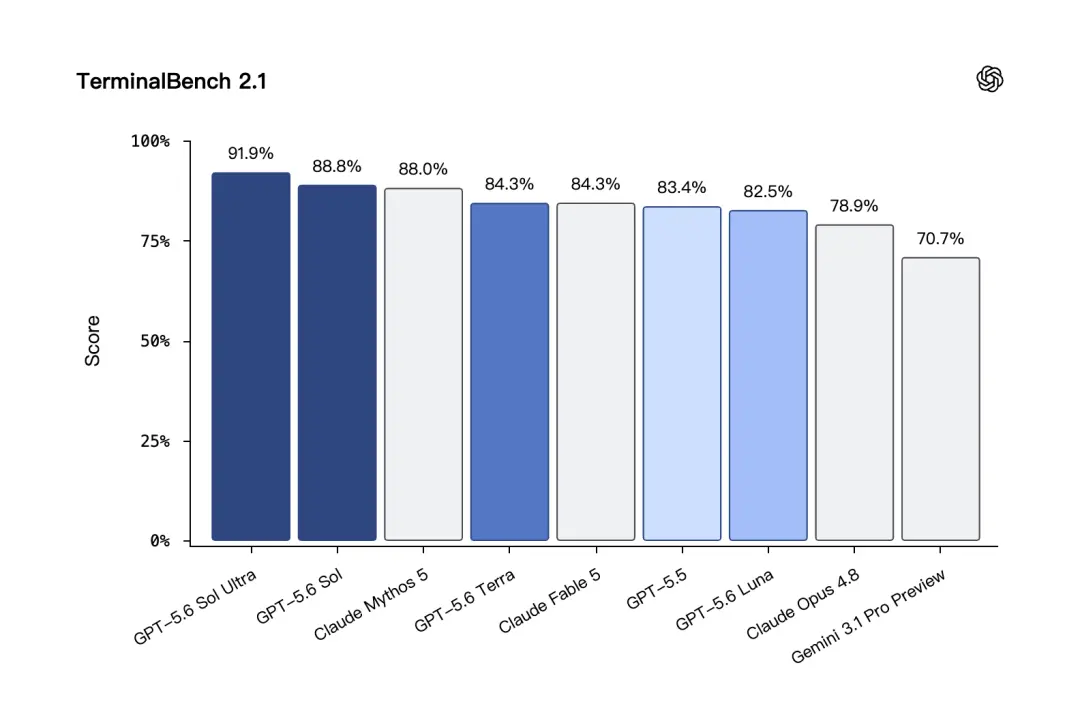
يعد Terminal-Bench 2.1 اختبارًا أقرب إلى عملية التطوير الحقيقية. فهو يختبر ما إذا كان النموذج يمكنه حل المشكلة خطوة بخطوة في بيئة سطر الأوامر. حقق GPT-5.6 Sol درجة عالية بلغت 88.8% في هذا الاختبار، وكانت النتيجة أعلى في الوضع Ultra.
ذكرت OpenAI على وجه التحديد أنه عندما يكون النموذج مفتوحًا على نطاق أوسع، سيتم إصدار مجموعة أكثر اكتمالاً من نتائج التقييم.
تيرا هو النطاق المتوسط.
لم يكن تقديم OpenAI لـ Terra طويلاً، ولكن موقعه واضح: إنه نموذج متوازن للعمل اليومي.
وهذا يعني أنها لا تسعى بالضرورة إلى الأقوى، ولكنها تحقق التوازن بين التأثير والسرعة والتكلفة. وأكد المسؤولون أن قدرات Terra تقترب من GPT-5.5، لكن سعره بنصف السعر.
في رؤية OpenAI، من المرجح أن يكون Terra هو الأكثر استخدامًا في سلسلة GPT-5.6. غالبًا لا تتطلب المهام المكتبية العادية أعلى الإمكانيات مثل Sol، ولكنها تحتاج إلى أن تكون مستقرة ورخيصة الثمن وسهلة الاستخدام.
في اختبار Terminal-Bench 2.1،حصل GPT-5.6 Terra على 84.3%، وهي نفس نسبة Claude Fable 5.
لونا هي الشريحة الأقل تكلفة.
يعد تحديد موقع OpenAI لـ Luna بسيطًا جدًا أيضًا: سريع ورخيص ومناسب للمهام واسعة النطاق وعالية التردد والحساسة للتكلفة.
على سبيل المثال، تلخيص الدفعات، وتصنيف النص، واستخراج المعلومات، والأسئلة والإجابة البسيطة، وما إلى ذلك. هذه المهام في حد ذاتها ليست بالضرورة معقدة، ولكن قد يكون حجم المكالمات كبيرًا جدًا. يتمثل دور Luna في تشغيل هذه المهام خفيفة الوزن بتكلفة أقل.
ومن بين هذه النماذج الثلاثة، تتولى Sol المسؤولية عن أعلى القدرات، وتيرا هي المسؤولة عن العمل اليومي، ولونا هي المسؤولة عن السرعة والتكلفة. قد يبدو الأمر خياليًا، لكن OpenAI تقوم فقط بإعادة تجميع الطبقات الناضجة بالفعل من صناعة النماذج الكبيرة.
لكنني أعتقد أن الاسم ليس مهما، طالما أنه رخيص وسهل الاستخدام.

القيمة مقابل المال
بمجرد النظر إلى الإعلان الرسمي، فإن المعايير التي أصدرتها GPT-5.6 Sol هذه المرة ليست كثيرة. قالت OpenAI نفسها إن الهدف الآن هو فقط السماح للعالم الخارجي بمعرفة أداء النموذج مسبقًا، لذلك ستشارك مجموعة من نتائج التقييم أولاً.
لكن مجموعة المعايير التي تم إصدارها لها اتجاه واضح، حيث تركز على ثلاثة مجالات: الكود، وعلم الأحياء، وأمن الشبكات.
ينتمي Terminal-Bench 2.1 المذكور أعلاه إلى اتجاه الكود. فهو يختبر ما إذا كان النموذج يمكنه إكمال عملية التطوير الحقيقية في بيئة سطر الأوامر، بما في ذلك التخطيط والتعديلات المتكررة وأدوات الاتصال والتحقق من النتائج.
بالإضافة إلى الكود، سلط OpenAI الضوء أيضًا على معيار بيولوجي: GeneBench v1.
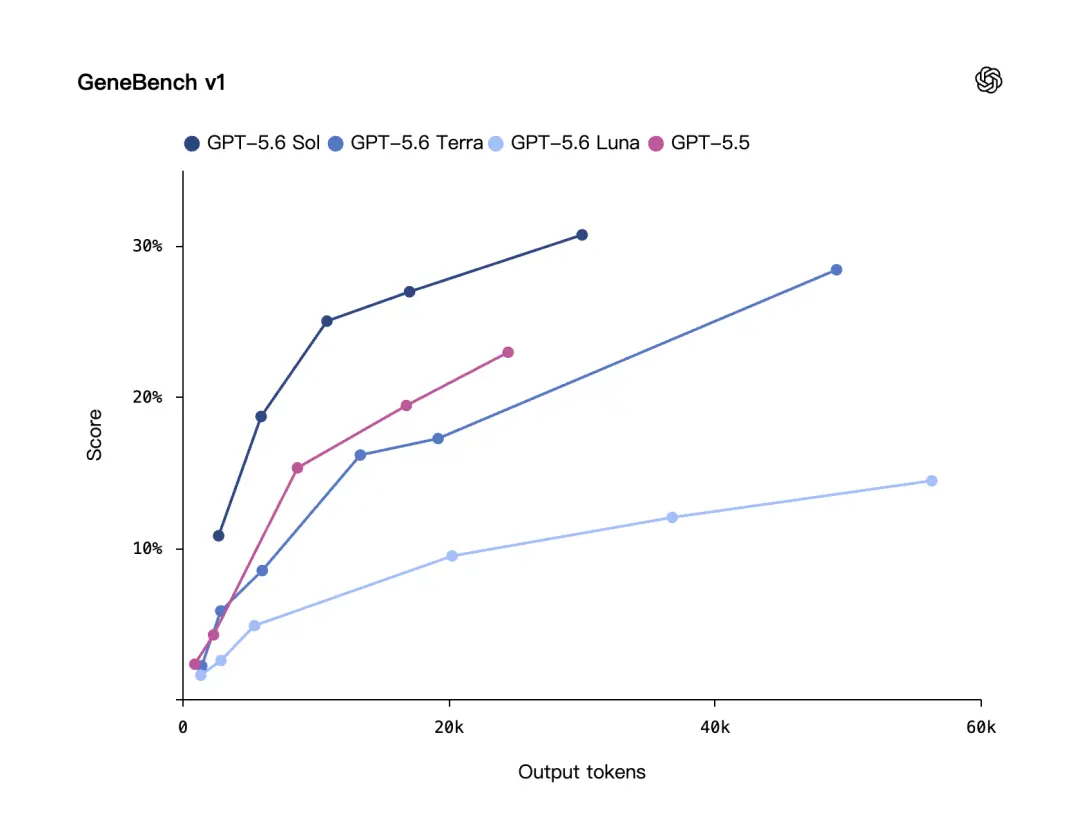
يقوم GeneBench v1 بتقييم مهام الجينوم والتحليل البيولوجي الكمي طويلة المدى، مع التركيز على ما إذا كان النموذج يمكنه التعامل مع مشكلات التحليل الأقرب إلى عملية البحث العلمي الحقيقية.
وفقًا لـ OpenAI، فإن أداء GPT-5.6 Sol أفضل من GPT-5.5 على GeneBench v1، واستخدم عددًا أقل من الرموز.
الاتجاه الرئيسي الثالث هو أمن الشبكات. تدعي OpenAI أن GPT-5.6 Sol هو أقوى نموذج أمان شبكي حاليًا، خاصة بالنسبة للمهام الأمنية طويلة المدى (بما في ذلك أبحاث الثغرات الأمنية والمهام المتعلقة باستغلال الثغرات الأمنية).
这里有一个benchmark叫 ExploitBench——它不是一般的安全问答,是更接近漏洞利用场景的评估。
قال OpenAI أنه على ExploitBench،أداء GPT-5.6 Sol يمكن مقارنته بأداء Mythos Preview، ولكنه يستخدم فقط حوالي ثلث الرموز المميزة للإخراج.
虽然,官方给出的这张图上还有一定差距。
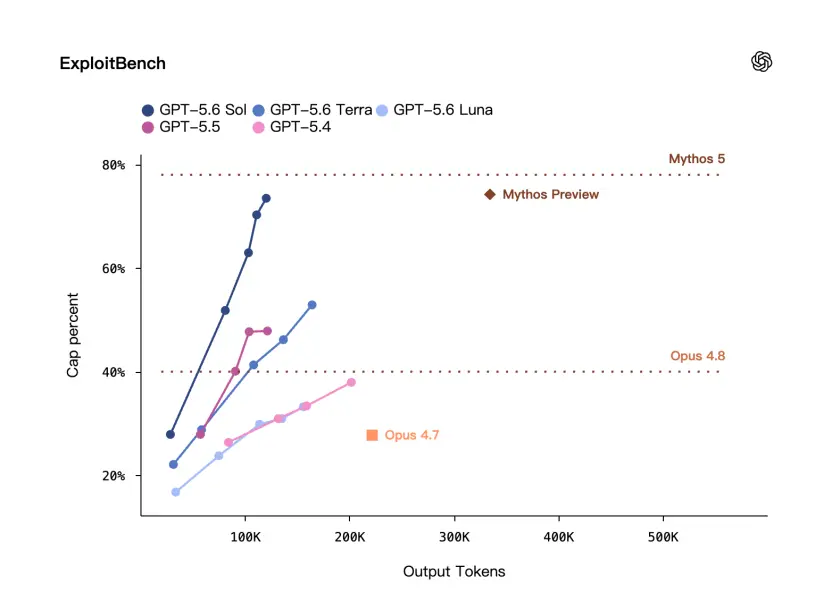
يمكن ملاحظة أن OpenAI أكد مرارًا وتكرارًا هذه المرة:وفي حين أنهم يتمتعون بقدرات عالية، إلا أنهم أيضًا فعالون للغاية.
يعني عدد أقل من الرموز المميزة للمخرجات أن النموذج قد يكون أكثر إيجازًا ويحتوي على عدد أقل من التحويلات عند إكمال مهام مماثلة، وقد يعني أيضًا أن تكلفة المكالمة الفعلية أكثر قابلية للتحكم.
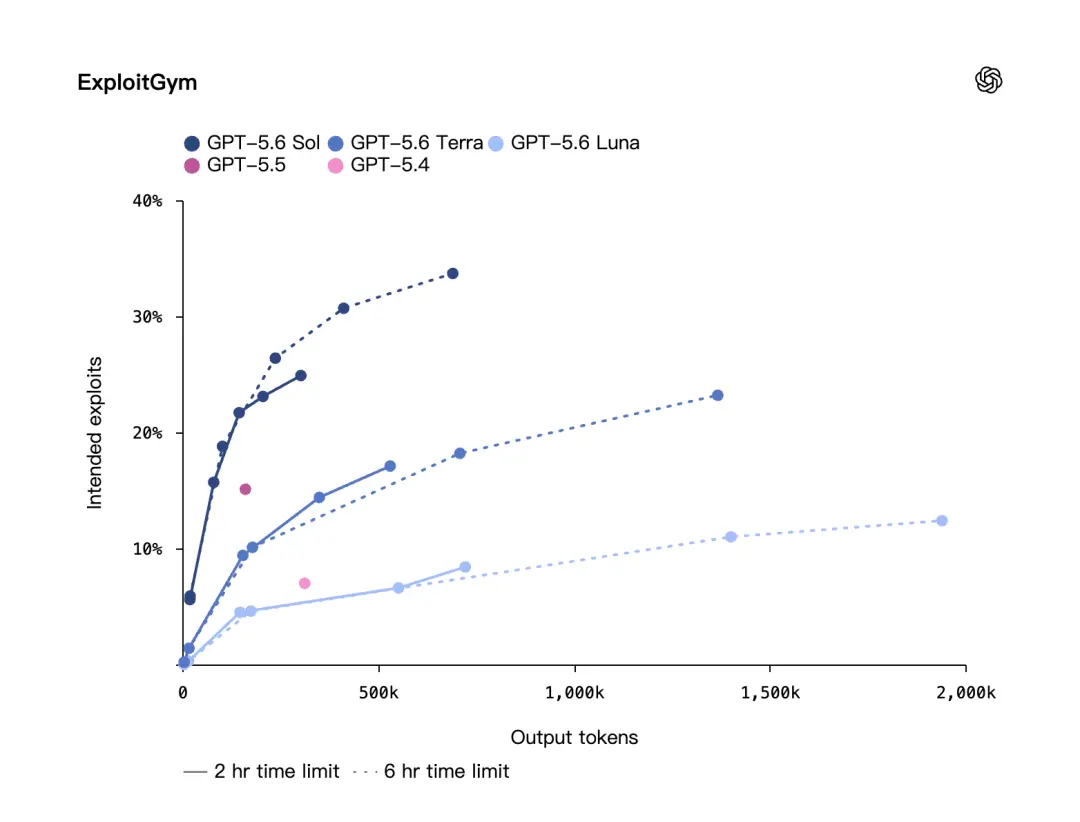
OpenAI还提到了另一个网络安全benchmark:ExploitGym。
这个benchmark是UC Berkeley研究人员与OpenAI以及其他前沿实验室合作创建的。OpenAI说,在ExploitGym上,GPT-5.6 Sol、Terra、Luna三档模型都显示出明显的网络安全能力提升,而且随着推理强度提高,表现也会变强。
وهذا يعني أن تحسين GPT-5.6 لا يتعلق فقط بجسم النموذج الأقوى، ولكن أيضًا يتعلق بطريقة التفكير. امنح النموذج مزيدًا من الوقت للتفكير ودعه يقوم بسلسلة أطول من التفكير، وستكون النتائج أفضل.

حول معاينة محدودة
إذا كانت Sol وTerra وLuna هي التغييرات السطحية لـ GPT-5.6، فإن ما يستحق المزيد من الاهتمام هو أن OpenAI لم يتم فتحه بالكامل هذه المرة.
وفقًا للإعلان الرسمي، سيكون GPT-5.6 حاليًا متاحًا فقط للمعاينة المحدودة في Codex وAPI لمجموعة صغيرة من "الشركاء الجديرين بالثقة".
علاوة على ذلك، تم إجراء هذه المعاينة المحدودة "بناءً على طلب حكومة الولايات المتحدة"، وتمت مشاركة قائمة الشركاء المشاركين في المعاينة مع حكومة الولايات المتحدة.
في الآونة الأخيرة، زادت حكومة الولايات المتحدة بشكل كبير من مشاركتها في نماذج الذكاء الاصطناعي المتطورة، وخاصة تلك التي تتمتع بتعليمات برمجية أقوى وأمن الشبكات وقدرات الوكيل.
في يونيو من هذا العام، أصدرت الحكومة الأمريكية أمرًا تنفيذيًا جديدًا يتعلق بالأمن السيبراني للذكاء الاصطناعي، يقترح إنشاء إطار طوعي للسماح لمطوري النماذج المتطورة بالاتصال وتقييم النموذج قبل إصداره على نطاق أوسع.
تفسير هذا الأمر الإداري من قبل المجتمع القانوني هو أنه ليس ترخيصًا إلزاميًا بالاسم، ولا هو نظام موافقة رسمي، ولكنه وضع إطارًا مؤسسيًا لمشاركة الحكومة في نموذج التقييم المسبق للإصدار.
يمكن اعتبار نموذج إصدار GPT-5.6 Sol المتمثل في "المعاينة الأولى على نطاق صغير ومشاركة القائمة مع الحكومة" بمثابة أول أثر واضح للتدخل الحكومي في عملية إصدار النموذج المتطور.
أوضحت OpenAI نفسها أيضًا في الإعلان أن سبب اتباع هذا النهج هو استكشاف عملية قابلة للتكرار مع الحكومة لدعم إصدارات النماذج المستقبلية.
السبب الأساسي وراء التدخل الحكومي هو أمن الشبكات.
في الإعلان الرسمي، يشغل أمان الشبكة مساحة كبيرة: تؤكد OpenAI على أن GPT-5.6 Sol هو أقوى نموذج لأمان الشبكة حاليًا ويمكنه تقديم مساعدة أقوى في المهام طويلة المدى مثل أبحاث الثغرات الأمنية، وتحليل الثغرات الأمنية، والدفاع الأمني؛ ومن ناحية أخرى، فإنها تنفق الكثير من المساحة لتوضيح أنها لم تتجاوز عتبة الحرجة السيبرانية الخاصة بها.
في إطار إعداد OpenAI، يتم تقسيم القدرات عالية المخاطر إلى مستويات مختلفة. ويعني الوصول إلى مستوى عالٍ أن النموذج قد يؤدي إلى تضخيم المخاطر الجسيمة القائمة؛ إن الوصول إلى المستوى الحرج يعني أن النموذج قد يؤدي إلى مخاطر جدية جديدة وغير مسبوقة.
لقد أكدت OpenAI مرارًا وتكرارًا أن GPT-5.6 Sol لا يصل إلى Cyber Critical. في الواقع، إنها تقول للحكومة والعملاء والجمهور: هذا النموذج قوي جدًا، خاصة في مهام أمن الشبكات، لكنه ليس قويًا بما يكفي لإكمال سلاسل الهجوم الأكثر خطورة على الشبكة بشكل مستقل.
تعتبر قدرات أمان الشبكة بمثابة سيف ذو حدين. وكلما كانت أقوى، زادت قدرتها على مساعدة المدافعين في العثور على نقاط الضعف، وكتابة التصحيحات، وإجراء اختبارات الأمان؛ ولكن على وجه التحديد لأنهم أقوياء للغاية، فإن الحكومة سوف تقلق أيضًا بشأن إساءة استخدامها.
على الرغم من أن OpenAI اعترفت بأن هذا الإصدار يتطلب استكشاف العملية مع الحكومة، إلا أنها أوضحت أيضًا في الإعلان الرسمي أنهم لا يعتقدون أن عملية الوصول الحكومية هذه يجب أن تصبح الآلية الافتراضية طويلة المدى.
الأساس المنطقي: إذا تأخرت أقوى الأدوات، فسيتأخر المستخدمون والمطورون والشركات والمدافعون عن الشبكات والشركاء حول العالم في الحصول على أفضل الأدوات.
بمعنى ما، تدخل النماذج المتطورة مرحلة إصدار جديدة.
عندما تتركز قدرات النماذج الكبيرة في مجالات مثل التعليمات البرمجية، وعلم الأحياء، وأمن الشبكات، وتنفيذ الوكيل، سيبدأ اعتبارها تقنية لديها القدرة على التأثير على أمن العالم الحقيقي.
وبمجرد النظر إلى التكنولوجيا بهذه الطريقة، فمن الصعب أن تظل حقوق النشر بالكامل في أيدي الشركة نفسها.