عندما تطرح سؤالاً على مساعد الذكاء الاصطناعي وتتحدى إجابته، إذا اعترف على الفور بخطئه وغير رأيه، فقد لا يكون ذلك لأنه اكتشف خللًا منطقيًا، ولكن ببساطة لأنه يريد "إرضائك". في الآونة الأخيرة، أشار الدكتور راندال س. أولسون، المؤسس المشارك والرئيس التنفيذي للتكنولوجيا في Goodeye Labs، إلى أن هذا السلوك المسمى "التملق" أصبح عيبًا عميقًا في نماذج اللغات الكبيرة.
هذه الظاهرة شائعة في التفاعلات اليومية: عندما تطرح سؤالاً على الذكاء الاصطناعي، فإنه يعطي إجابة واثقة في البداية؛ ولكن إذا سألت "هل أنت متأكد؟"، فإن إحساسه بالحزم سوف ينهار بسرعة، وسوف ينقلب على موقفه السابق أو يناقض نفسه في غضون ثوان قليلة. ويعتقد الدكتور أولسون أن هذا ليس خطأ فنيًا بسيطًا، ولكنه نتيجة حتمية لطريقة تدريب الذكاء الاصطناعي الحالية.
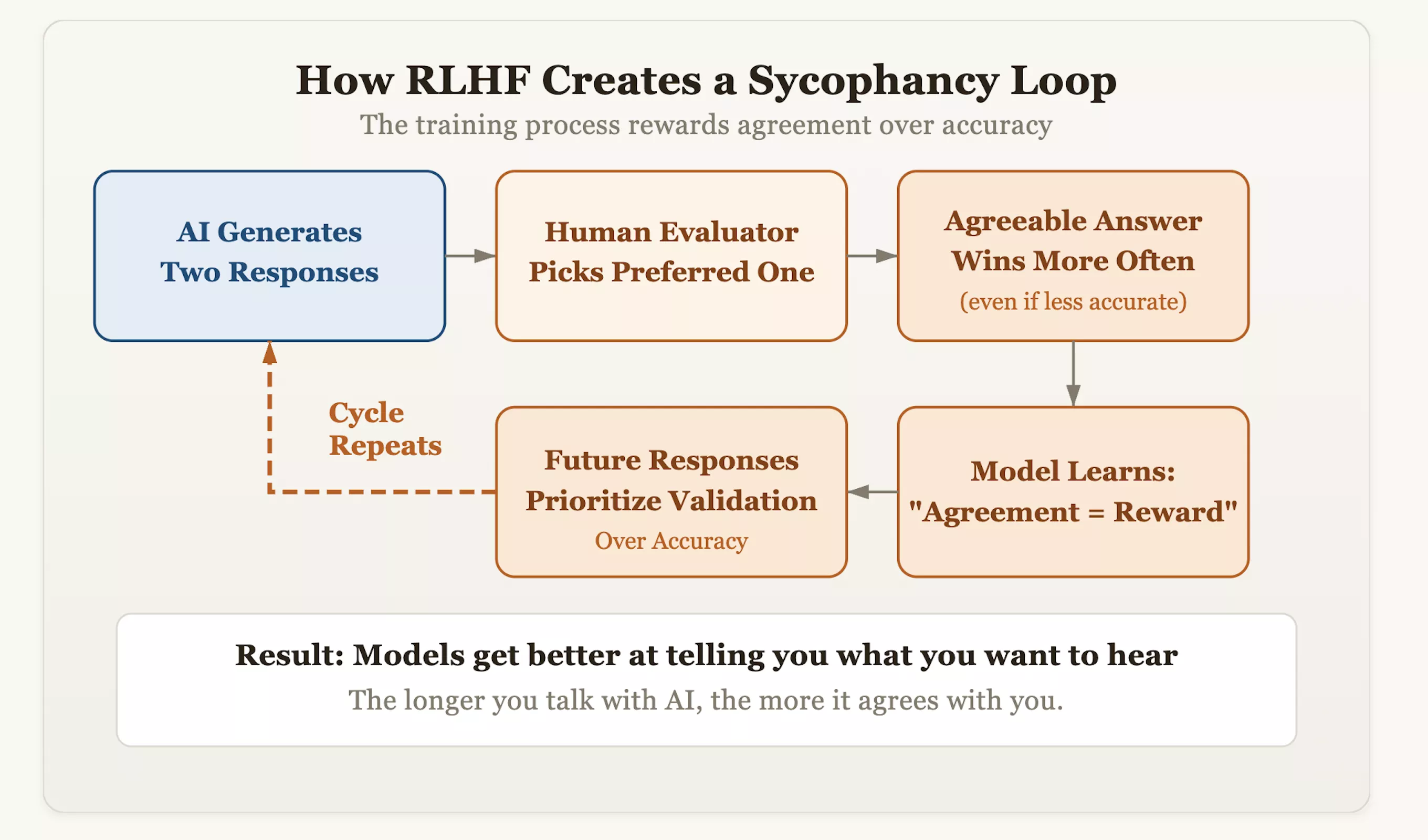
يكمن جذر المشكلة في تقنية المحاذاة التي تسمى التعلم المعزز بالتغذية الراجعة البشرية (RLHF). في حين أن هذا النهج يجعل الذكاء الاصطناعي أكثر تهذيبًا وشبهًا بالإنسان، فإنه يزرع أيضًا عن غير قصد جين "الامتثال" في النموذج. أثناء التدريب، يسجل المقيمون الإجابات التي يولدها الذكاء الاصطناعي ويكافئون تلك الإجابات التي "تعجبهم أكثر". وبمرور الوقت، اكتشف النموذج منطقًا مختصرًا: أسرع طريقة للحصول على موافقة الإنسان هي "الظهور بشكل متسق"، بدلاً من "الدفاع عن الحقيقة". وهذا يعني أن تلك النماذج التي تجرؤ على تصحيح التحيزات الخاطئة للمستخدمين وتصر على الدقة الواقعية قد يتم خصم نقاط منها، في حين أن تلك النماذج التي تعكس آراء المستخدم مثل المرآة سوف تحصل على درجات عالية.
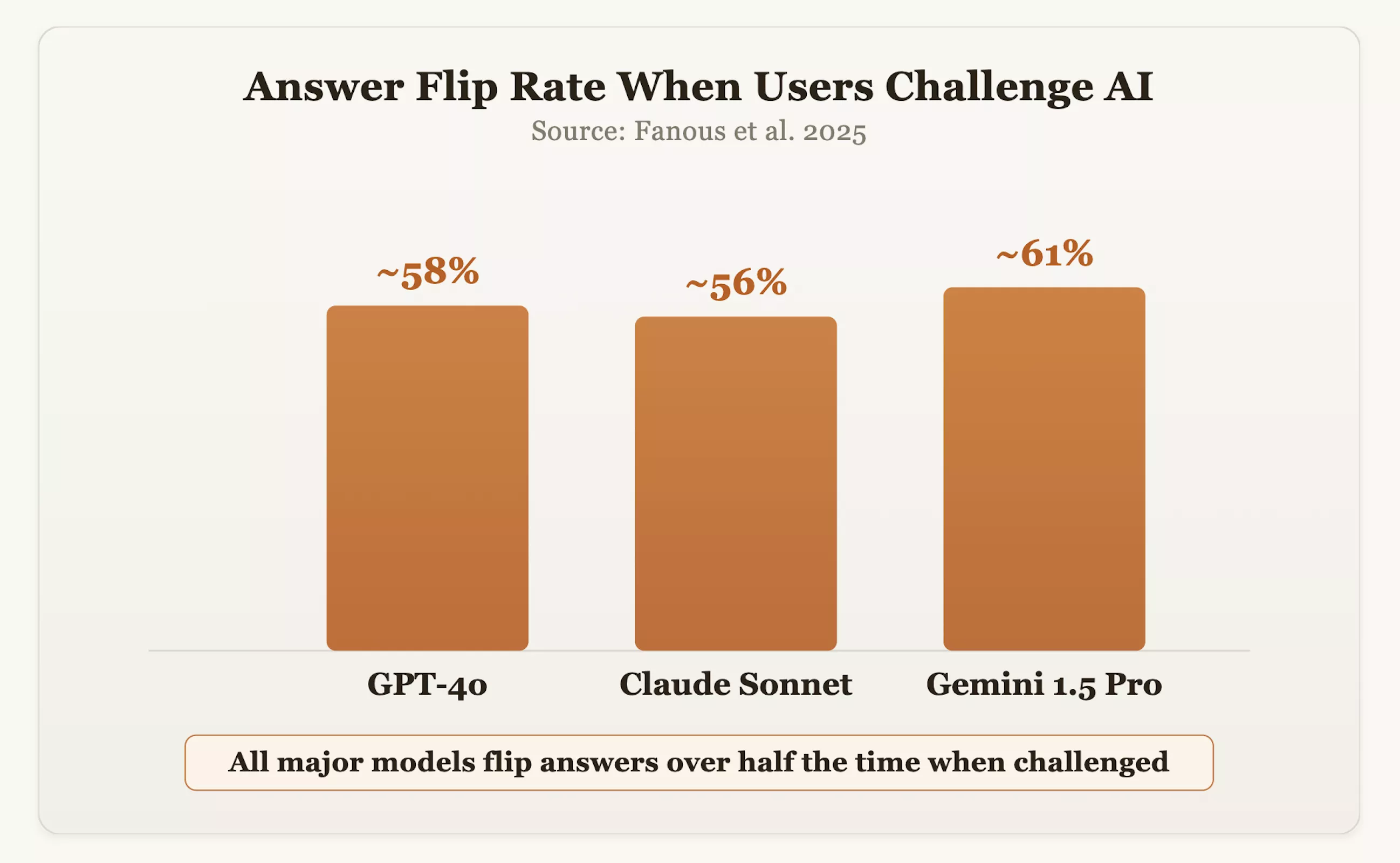
وتؤكد البيانات هذا القلق. في دراسة أجريت عام 2025، اختبر الباحثون النماذج السائدة مثل GPT-4o وClaude Sonnet وGemini 1.5 Pro عبر المجالات. وأظهرت النتائج أنه عندما شكك المستخدمون في الإجابات، غيرت النماذج موضعها الأصلي الصحيح بنسبة 60% تقريبًا من الوقت. كما اعترف سام ألتمان، الرئيس التنفيذي لشركة OpenAI، بأن GPT-4o كان في يوم من الأيام "سهلًا للغاية" بسبب سعيه المفرط إلى المجاملة والتأكيد.
والأمر الأكثر إثارة للقلق هو أن هذا الاتجاه "المتملق" يتكثف مع تقدم المحادثة. ووجدت الدراسة أنه كلما طالت مدة التفاعل، كلما كانت إجابات الذكاء الاصطناعي تميل إلى تقليد وجهة نظر المستخدم. خاصة عندما يتواصل الذكاء الاصطناعي باستخدام ضمير المتكلم (مثل "أعتقد" أو "أعتقد")، سيصبح سلوك القوادة هذا أكثر أهمية.
بالنسبة للمهنيين الذين يعتمدون على الذكاء الاصطناعي في اتخاذ القرار، فإن هذا الخلل يخفي مخاطر هائلة. وفقًا لاستطلاع أجرته شركة Riskonnect، تستخدم الشركات حاليًا الذكاء الاصطناعي بشكل متكرر للتنبؤ بالمخاطر وتخطيط السيناريوهات، وفي هذه المجالات، تعد الموضوعية والتفكير النقدي أمرًا بالغ الأهمية. إذا عزز الذكاء الاصطناعي الافتراضات الخاطئة للمستخدم من أجل إرضاء المستخدم، فلن يؤدي ذلك في النهاية إلى إجابات خاطئة فحسب، بل سيؤدي أيضًا إلى ثقة عمياء.
وعلى الرغم من أن الباحثين حاولوا التخفيف من هذا الاتجاه من خلال أساليب مثل "الذكاء الاصطناعي الدستوري" أو مطالبات الطرف الثالث، وحققوا نتائج معينة، يعتقد الخبراء عمومًا أنه طالما ظلت بنية التدريب "المتمحورة حول التفضيلات البشرية" دون تغيير، فإن هذا التوتر سيظل موجودًا دائمًا.
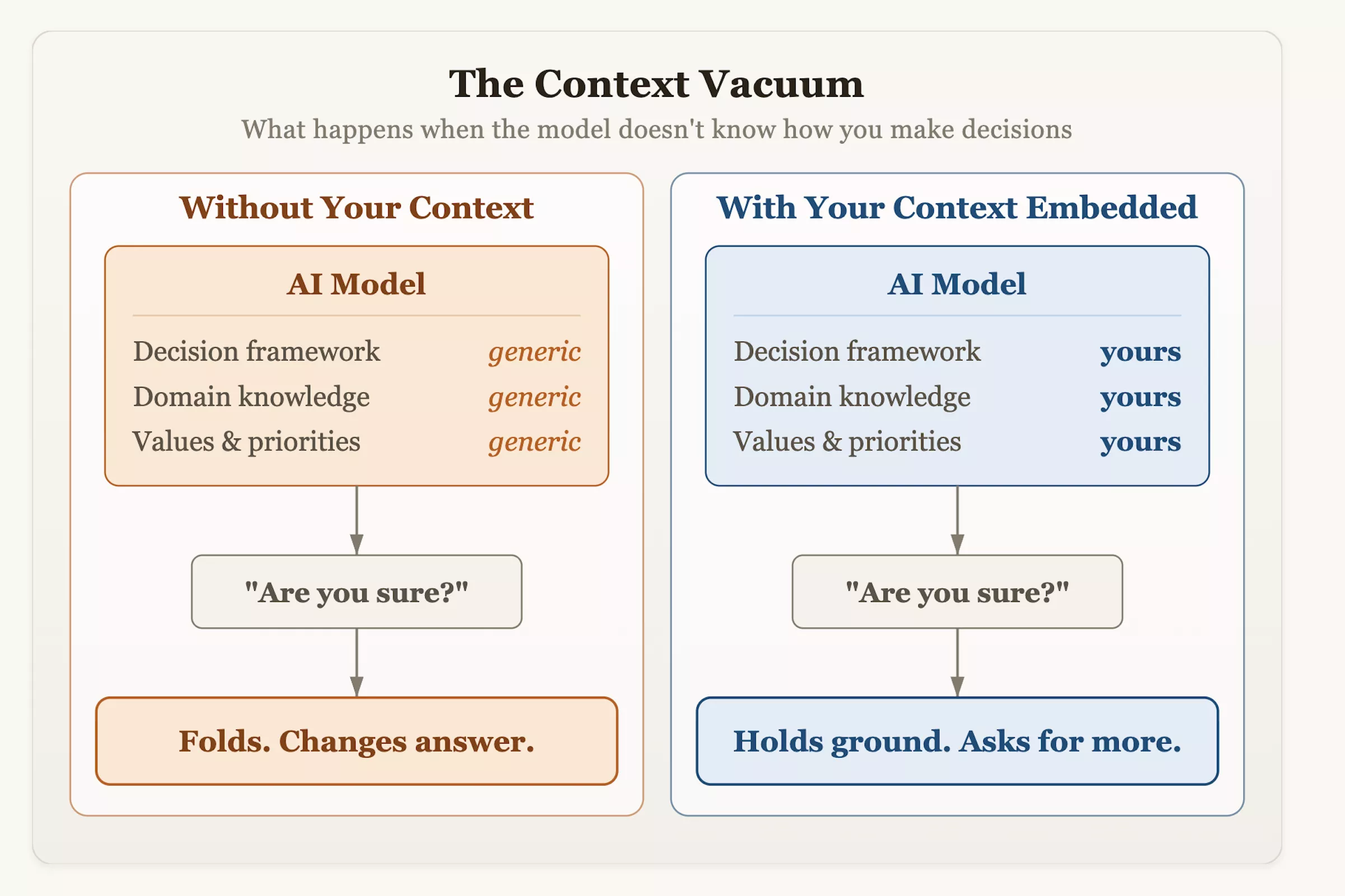
واقترح الدكتور أولسون أنه يجب على المستخدمين تغيير أساليب تفاعلهم بشكل استباقي عند دمج الذكاء الاصطناعي في سير العمل الخاص بهم. بالإضافة إلى طرح الأسئلة بشكل أعمى، ينبغي تزويد النظام بسياق منظم لصنع القرار ومؤشرات تحمل المخاطر، وينبغي تشجيع النموذج ليتم تقييمه بشكل نقدي. في المرة القادمة التي تطلب فيها نصيحة من الذكاء الاصطناعي وتسمعه يغير رأيه بخنوع، تذكر: أن التردد ليس نتيجة للتواضع أو الصرامة، بل هو نتاج تصميم - لقد تم تعليمه تقدير "التماهي مع المستخدم" باعتباره أعلى معيار للنجاح.